Design System Architect
Fluent, Fluently: Architecting a System for Model Legibility
I defined how Fluent exposes itself to AI and how AI could help build Fluent.
What I delivered
- Built the spec skill framework, which has shipped 24 components to date, each buildable by a model from a single source in about 7 minutes, with that same source emitting cross-platform output.
- Shifted the source of truth upstream: Figma specs and documentation are now byproducts of the fluent-design repo, not the other way around.
- Made the markdown/YAML split the team's default contract, the line humans and models both build against.
What it enables
- Models can read the system, so the team creates and audits artifacts with AI instead of by hand. Less pixel-pushing, more leverage.
- Lifecycle is testable, not just declared: drift detection catches when a surface diverges from its spec, so coherence holds as the system scales.
- Generation replaces lookup: because the system's decisions live upstream, makers can produce Fluent-correct UI on demand instead of hunting for the right pattern after the fact.
- The architecture forks: the Microsoft AI (MAI) design system team is already adapting the bi-directional model for its own AI knowledge work.
And Beyond is the framing case: how I envisioned and evangelized an AI-era design system. This is the tactical case: how Fluent specifically exposes itself to models in code, schemas, and repo structure.
The problem
Design systems of the past assumed humans authoring guidance to be read, interpreted, and used by other humans. This left wiggle room for nuance, assumptions, and opinions. Models can’t operate that way and the gaps in Fluent made that clear. Introducing AI into product-making meant we needed to change how we built the system for it.
In turn, AI could help create and maintain the design system faster than humans alone, but only if Fluent was structured correctly.
The architectural insight
The answer was to make the whole system bi-directional.
Build the system for model consumption. Make Fluent’s artifacts AI-readable by default, so models can reference and act on the system without fabricating design decisions.
Use the model to help build the system. Once Fluent is structured well enough for models to consume, use AI to help create, maintain, and audit the system itself. Less pixel-pushing, more leverage.
Building the infrastructure
The mental model
Constraints needed to live upstream of the model and inform its understanding, not patch onto its output post-hoc.
There’s a difference between asking did AI do this right after it’s already output something, and telling it here’s how to do it right before it’s ever prompted. I pushed the shift from Fluent as latent information to generative foundation.

"I had a slew of token documentation I didn't know what to do with, and when I brought it to you, you saw something I didn't. My docs became the first use case in the Fluent-design repo."
— Karlee Boillot, Senior Product Designer
I invited a tokens expert in to run an ad-hoc experiment with me. I knew the new tokens system she worked on was semantic and mathematically derived. The hypothesis: we can structure this data for consistent AI-readability, then test how well a model can apply or extend the tokens based on it. We generated schemas from Figma docs, creating structured, machine-readable artifacts from visual-heavy frames meant for humans.
Then, we evaluated it to ensure it could answer correctly based on the schema, not just guess based on its training data. The tokens expert was the SME who could validate AI’s findings. If it output an incorrect answer, I spelunked with her help to find the flies in the ointment.
The component schema
Component knowledge needed to be encoded as a scalable typed contract, where models and humans each understood what they needed to contribute.
"I really enjoyed working with you on the spec schema from when it first started all the way to where it is now. Your knowledge in making sure that these can be generalized and templatized has made it easier for me and the rest of the team to start thinking about how we structure these component markdowns easier."
— Toshie Rashtavie, Product Designer 2
The spec schema identifies the least common denominators across all our components and gives them a structured data format. It instructs models on what information about a component is necessary, what needs to come from a human, what it can safely extrapolate, and how it should reason. As part of the process, AI outputs a rationale, so the reasoning, not just its final ouptut, is visible and checkable. (Because don’t forget the flies in the ointment.)
The schema was substrate. It served as both a goal for people to snap to in structuring tribal knowledge, and an artifact to get them started. To prove it out, I partnered with an expert at speccing and component-building in Figma. I owned the shape of the information; he owned the component expertise. Together we built a more sophisticated spec creation skill on top of it, maintaining the clear bounds of AI vs human contribution. He took it further on his own, developing a Figma pipeline that the spec fed into. The schema became infrastructure other people built on, not just a doc I authored.
The taxonomy
Some files are the first-class assets the system delivers to our subscribers (our design language, tokens, the components themselves). Other files are the operations and procedures that maintainers need to build, audit, and govern the system. The split is asset versus operation, noun versus verb, not function versus function.
"Her guidance is what ensures coherence. She sees beneath the surface and shapes how components should work from a system perspective, making complex experiences feel rational and connected."
— System Shaper Award nomination
Asset skills are the system’s source of truth. Our button/SKILL.md file isn’t documentation about a button. It IS the button, encoded as a structured contract a model can read. The first leg of the loop: build the system for model consumption.
Within assets, content splits one level deeper into two file types, used together but never confused:
- Markdowns carry semantic intent: guidance for how a system should be applied and extended, inference rules and guardrails. This is what models need to make defensible choices.
- YAMLs carry deterministic values: the exact list of tokens, variants, and constraints that a model must use rather than fabricate. This is what models must not improvise on.
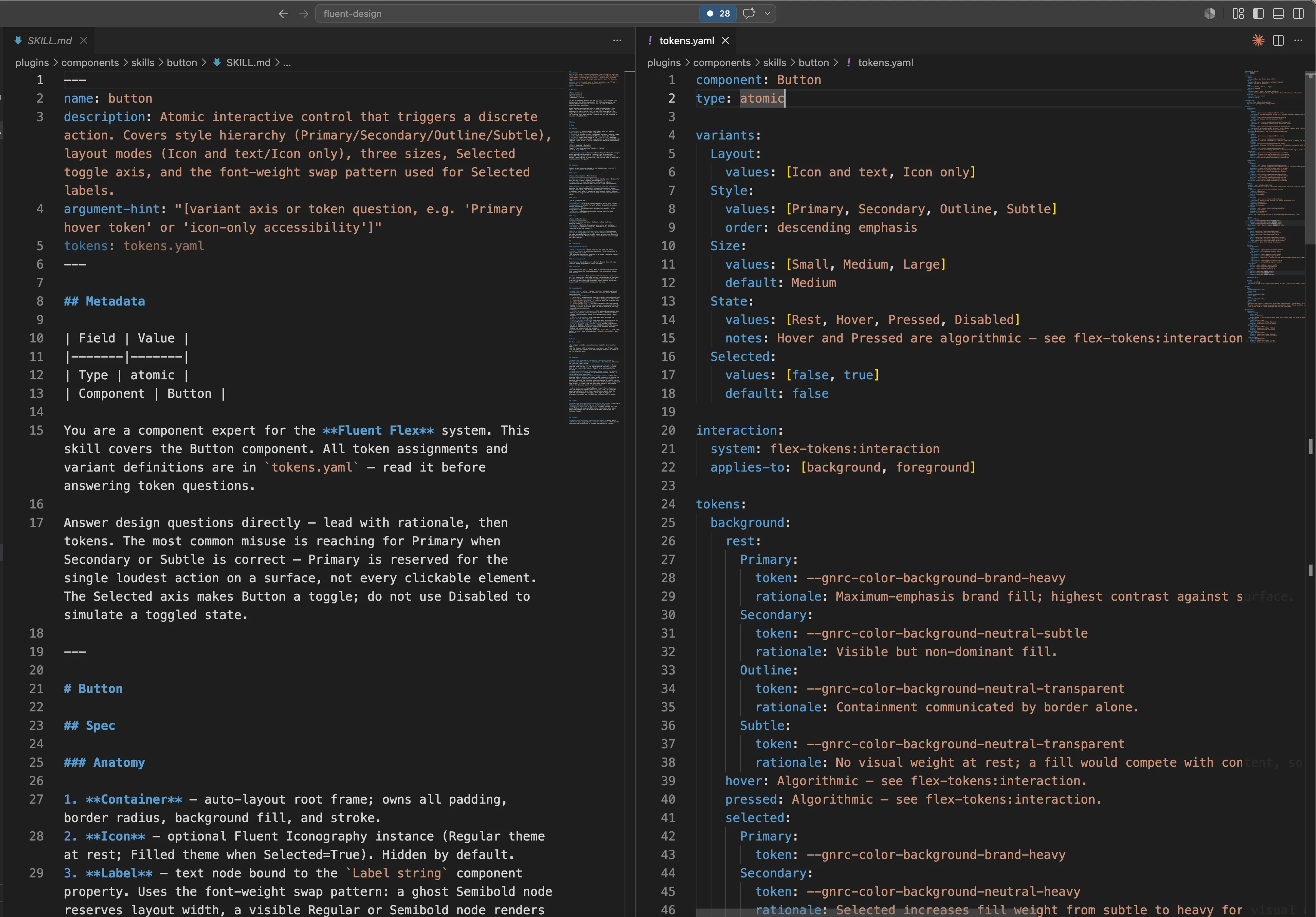
The button component in two files. SKILL.md (left) carries the reasoning; tokens.yaml (right) carries the values.
Operational skills are reusable processes that act on assets to produce downstream artifacts of the system: Figma assets, docs, token audits. They enable AI-enhanced workflows for managing and improving the system. Our operational skills are the second leg of the loop: Use the model to help build the system.
The repo
"Part of that goooood work was a new repo for Fluent to work out of, which was much needed; that space and its organization has allowed an insane amount of progress from lots of different people on our team."
— Stephanie Sullivan, Senior Product Designer
Constraints, schemas, and skills needed to live in one place, a source of truth queryable in both directions, not scattered across tools that drift.
I architected the fluent-design repo and steward its decisions. The design system team builds inside it, refining the model as we learn what works.
The repo is the new source of truth, but the flow stays bi-directional. The ideal direction is markdown outward: Figma specs, component documentation, and code references all derive from here. But the team can also work in Figma, with checks in place to catch those changes and reflect them back to the source of truth, so things stay updated and maintenance stays low. Work anywhere, ship everywhere. The repo is the system’s center of gravity in one place.
Drift detection
Source of truth only holds if something enforces it. Without an audit, drift between spec and surface stays invisible until someone notices.
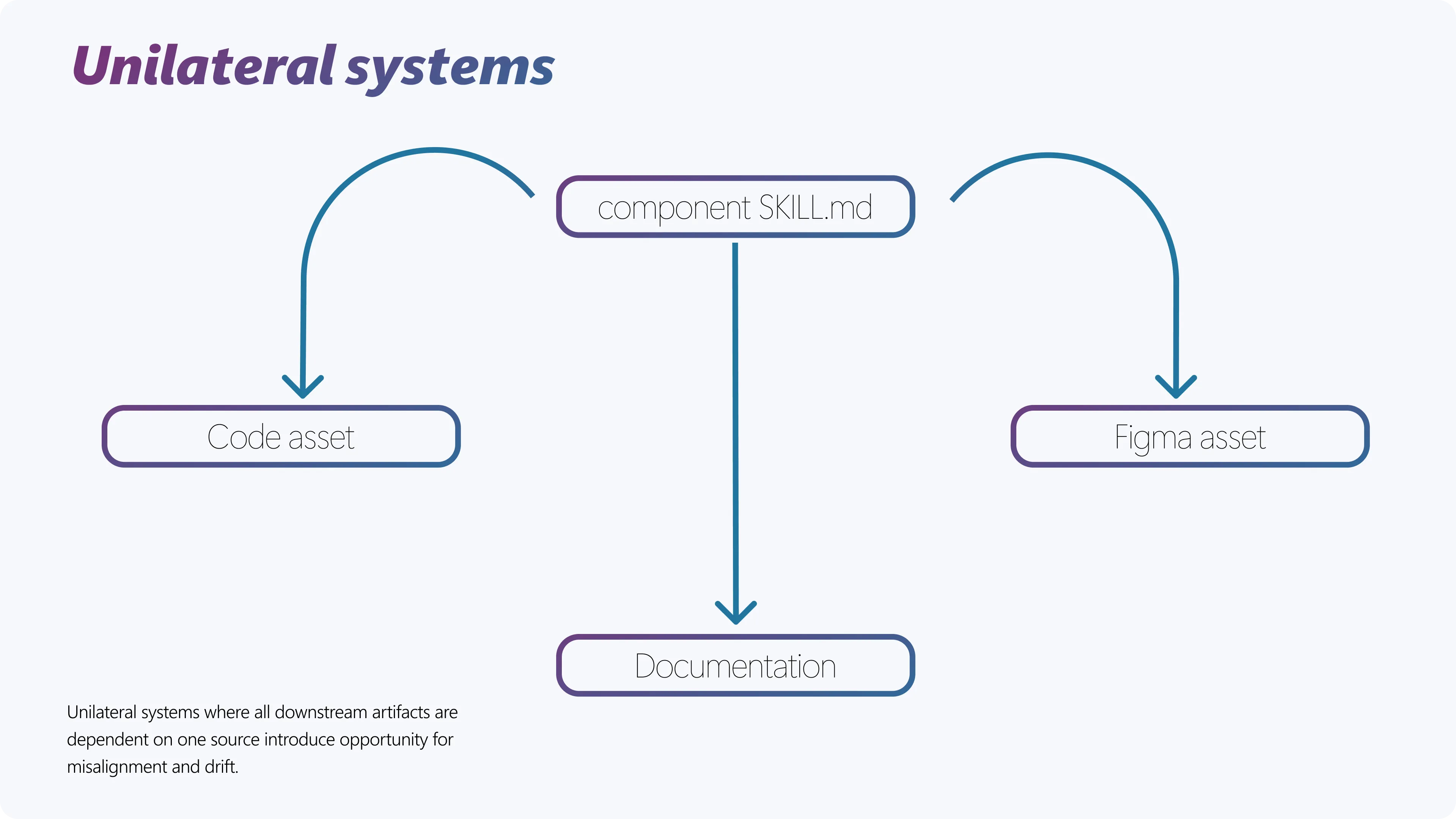
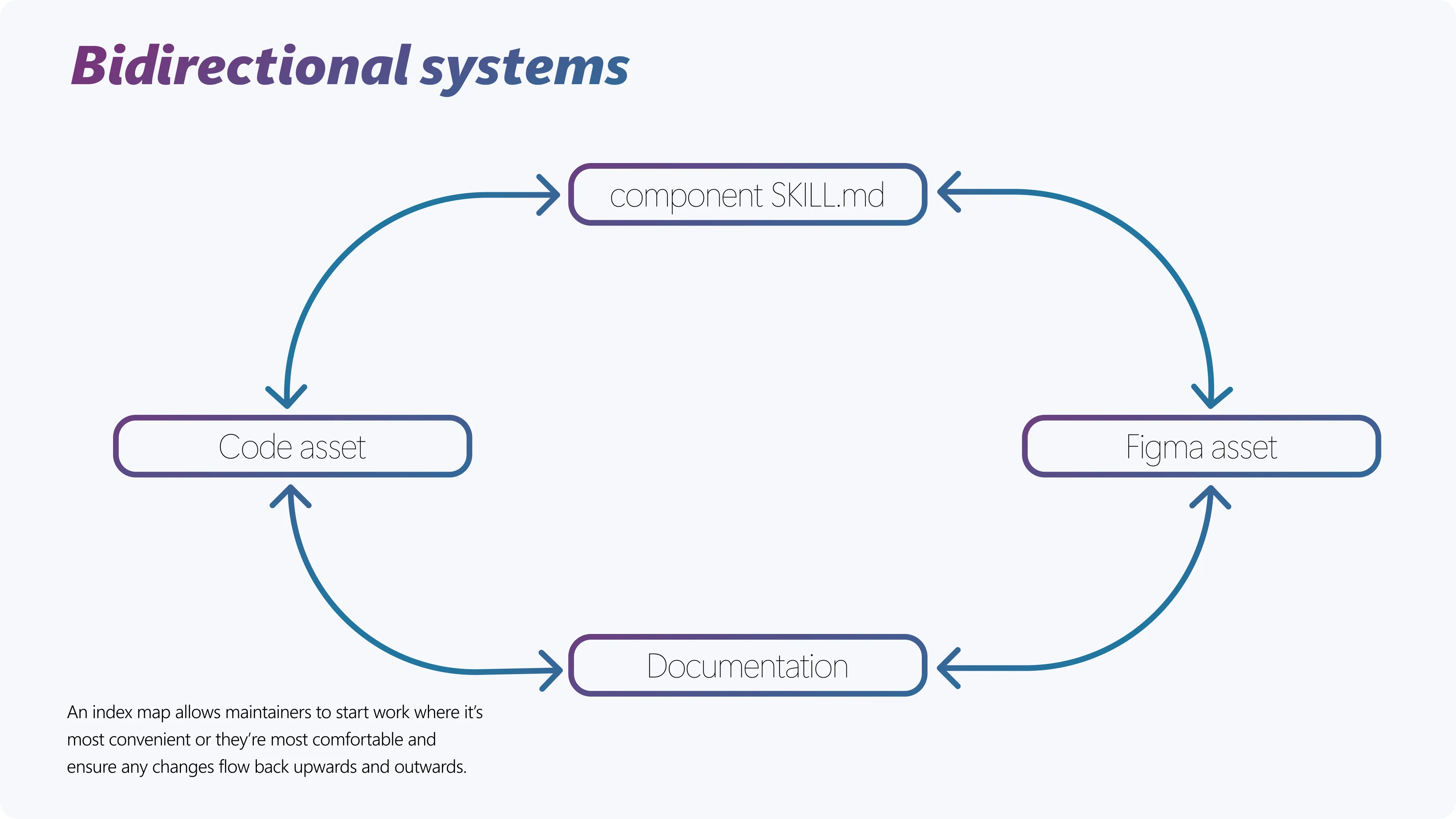
Unilateral (left) versus bidirectional (right). The index map closes the loop.
I built the enforcement as a pair. A component-map.yaml indexes every component’s spec and its surfaces. A drift-detect skill walks each surface, compares it back to the spec, and files a GitHub issue when something doesn’t match. Lifecycle becomes testable instead of declared.